Optical Character Recognition:-
Optical character recognition or optical character reader is the electronic or mechanical conversion of images of typed, handwritten, or printed text into machine-encoded text, whether from a scanned document, a photo of a document, a scene photo, or from subtitle text superimposed on an image.
- The first step of OCR is using a scanner to process the physical form of a document.
- Once all pages are copied, OCR software converts the document into a two-color, or black and white, version
- The scanned-in image or bitmap is analyzed for light and dark areas, where the dark areas are identified as characters that need to be recognized and light areas are identified as background
Pattern Recognition & Feature Detection
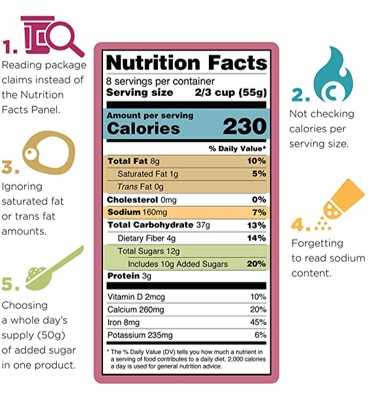
Label Reading:-
Label-reading skills are intended to make it easier for you to use the Nutrition Facts labels to make quick, informed food decisions to help you choose a healthy diet. Overview | Serving Information | Calories | Nutrients | The Percent Daily Value (%DV) | Nutrition Facts Label Variations.
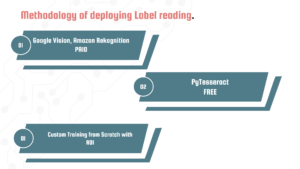
Methodology of deploying Label reading:-
Installing Libraries:-
- Tesseract-OCR Executable: https://www.pantechsolutions.net/media/attachment/file/t/e/tesseract-ocr-w64-setup-v5.0.0-alpha.20200328.exe
- Pytesseract: pip install pytesseract
Source Code: Extracting Text from Image – Pytesseract:-
try:
from PIL import Image
except ImportError:
import Image
import pytesseract
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
def recText(filename):
text = pytesseract.image_to_string(Image.open(filename))
return text
info = recText('test.png')
print(info)
file = open("result.txt","w")
file.write(info)
file.close()
print("Written Successful")
What does Optical Character Recognition mean?
Optical character recognition (OCR) technology is a business solution for automating data extraction from printed or written text from a scanned document or image file and then converting the text into a machine-readable form to be used for data processing like editing or searching.
OCR solutions improve information accessibility for users
A common application of OCR technology is the automated conversion of an image-based PDF, TIFF, or JPG into a text-based machine-readable file. OCR-processed digital files, such as receipts, contracts, invoices, financial statements, and more, can be:
- Searched from a large repository to find the correct document
- Viewed, with search capability within each document
- Edited, when corrections need to be made
- Repurposed, with extracted text sent to other systems
One comment